對訓練強化學習模型的過程來說,其實許多樣本不是太重要,舉訓練小恐龍的例子,如果移動過程仙人掌出現的次數不頻繁,我們可以認定很多時候的狀態(state)是不重要的(大部分就散散步),基於這個我們可以思考,是否能有個方法判斷該狀態(state)的重要性呢?
這時Duel DQN就出現了!使得神經網路在學習過程中,除了Q估計出action值外(advantage),會再加上一個value function去估計目前state的重要性。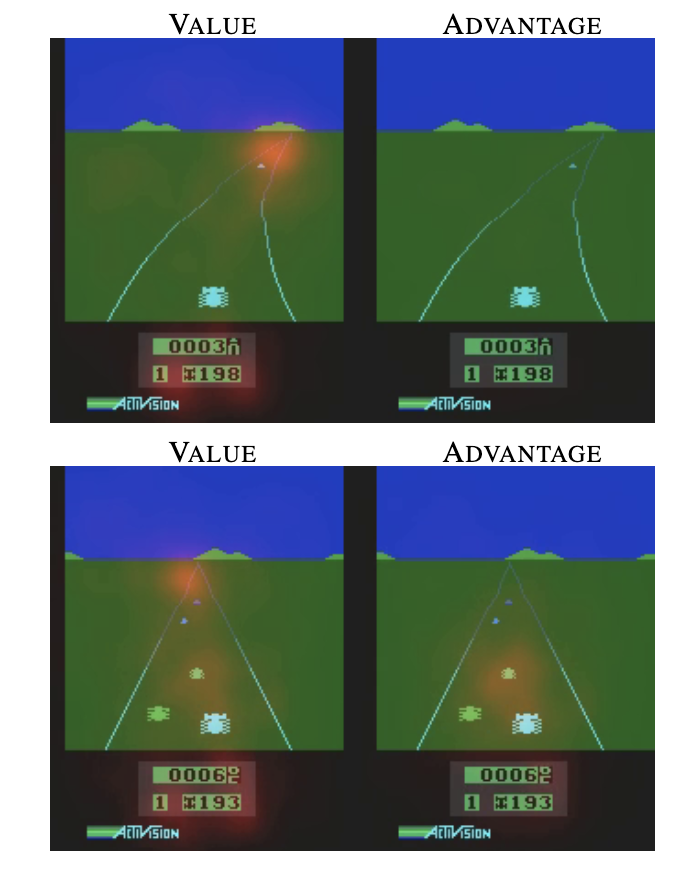
只是單純加上對state的評估,收斂結果好很多!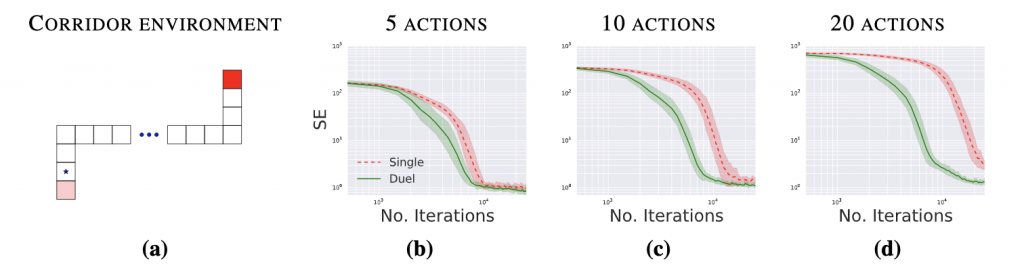
另外補充因為尾部advantage跟value做連結了,所以對於Q值來說,你無法解析最後出來的Q值哪部分是advantage output,哪個部分是value output,為了解決此問題,我們會在advantage做去中心化減去平均值。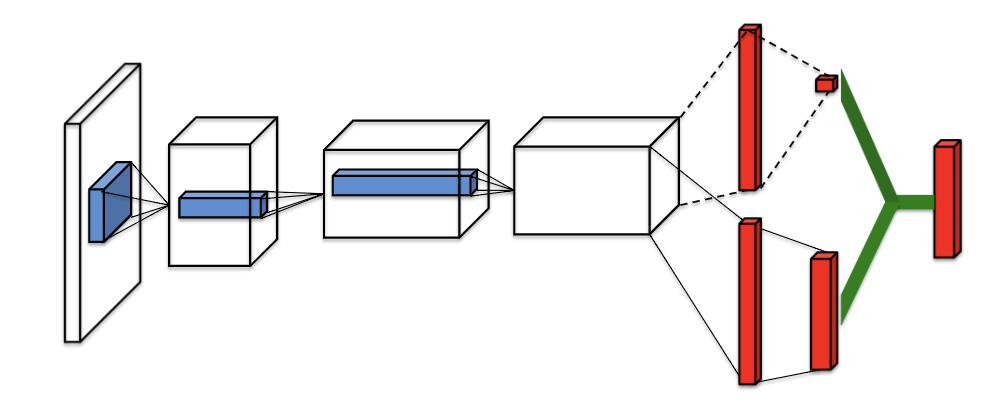
實作dueling DQN的方法很簡單,只要在尾部地方做點改變就好了!outputlayer = Lambda(lambda a: K.expand_dims(a[:, 0], -1) + a[:, 1:] - K.mean(a[:, 1:], axis=1, keepdims=True), output_shape=(nb_action,))(y)
參考:https://github.com/germain-hug/Deep-RL-Keras/blob/master/DDQN/agent.py
Dueling DQN還有其他正規化方法,筆者這裡介紹的是最常用的,其他有興趣的話同學可參考備註的論文研讀,好哩明天會準備介紹如何對replay memory做優化,大家明天見拉!~
1.Dueling DQN → https://arxiv.org/abs/1511.06581
2.Difficulty in understanding identifiability in the “Dueling Network Architectures for Deep Reinforcement Learning” paper → https://bre.is/6TwDuC5X


 iThome鐵人賽
iThome鐵人賽